
Ciencia y Tecnología
Creíamos que ningún modelo chino de IA se acercaría pronto a Fable 5 o GPT-5.5. Entonces llegó GLM-5.2


Hace unos días la startup china Zhipu AI (Z.ai) anunció el lanzamiento de su nuevo modelo abierto de IA, GLM-5.2. Lo hizo presumiendo de unas prestaciones asombrosas que lo acercaban mucho a los mejores modelos cerrados de OpenAI y Anthropic, algo que parecía imposible. Pues bien: cuantos más análisis se realizan del modelo, mejor parado queda. Puede que estemos ante el principio de algo muy importante. Un cambio de tendencia.
GLM 5.2. La startup china Z.ai lleva ya mucho tiempo lanzando distitnas versiones de su modelo de IA GLM, pero la última es sin duda la más sorprendente porque su rendimiento es especialmente prometedor. Cuenta con 744.000 millones de parámetros (744B), de los cuales 40.000 son los que se mantienen activos. Estamos ante un modelo con una ventana de contexto de un millón de tokens y una nueva arquitectura llamada IndexShare/IndexCache.
Mejor que GPT-5.5, muy cerca de Opus 4.8. La startup mostró cómo el rendimiento de GLM-5.2 es extraordinario en tareas de programación. En el test FrontierSWE, el más exigente de los existentes actualmente, GLM-5.2 superó a GPT-5.5 y solo Opus 4.8 fue superior por un margen muy pequeño. Lo mismo ocurrió con otras pruebas como PostTrainBench o SWE-Marathon, que por ejemplo evalúa el comportamiento del modelo en larguísimas sesiones de programación autónoma.
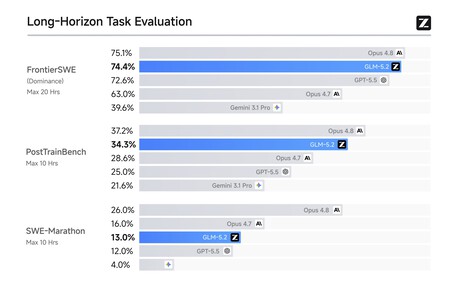
Fuente: Z.ai.
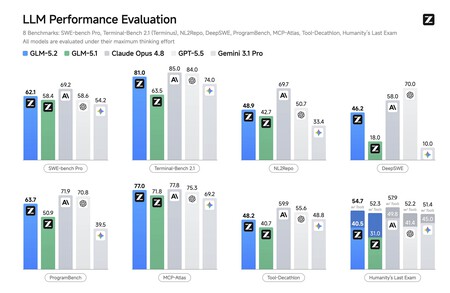
En otras muchas pruebas la foto fue idéntica: el modelo ha dado un salto espectacular desde la versión 5.1, y es en muchos tests casi tan bueno (o mejor) como los mejores de OpenAI, Anthropic o Google.
Pero es que no solo lo dicen ellos. Artificial Analysis, una reputada firma independiente que mantiene un ránking actualizado del rendimiento de los nuevos modelos de IA que van llegando al mercado, confirma los datos de la propia Z.ai. En sus pruebas indica cómo el "índice de inteligencia" de GLM-5.2 es ahora de 51 puntos. Solo le superan GPT-5.5 (55), Claude Opus 4.8 (56) y Claude Fable 5 (60).
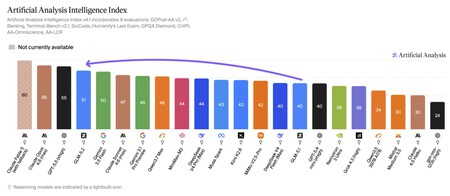
Fuente: Artificial Analysis.
Este modelo abierto chino deja atrás al nuevo Gemini 3.5 Flash, pero también a competidores chinos como Qwen 3.7 Max, MiniMax-M3 o DeepSeek V4, entre otros. El salto de calidad desde GLM-5.1 es, insistimos, sobresaliente, mucho mayor que el que al menos según este índice se vio desde Opus 4.8 a Fable 5.
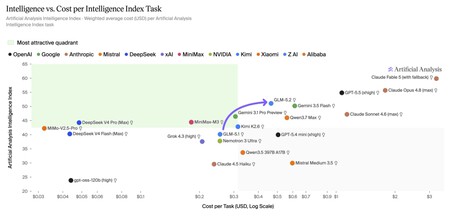
El salto de rendimiento es espectacular, aunque es cierto que el precio comparativo para resolver las tareas propuestas en el benchmark sube de forma sensible. Fuente: Artificial Analysis.
Pero no es perfecto. El informe de Artificial Analysis, eso sí, muestra que aunque GLM-5.2 es muy fuerte en ámbitos como la programación, flojea en otros. Por ejemplo, está lejos de ser tan fiable como Fable 5, GPT-5.5, Claude 4.8 o Gemini 3.1 Pro en cuanto a respuestas correctas, que también es menor en proporción a la de sus competidores. Sin embargo ha reducido de forma notable sus alucinaciones.
Y es mucho (muchísimo) más barato. Pero es que además de ser fantástico en muchos ámbitos, es mucho más barato que sus competidores. Mantiene el precio por millón de tokens de entrada/salida de su antecesor (1,4/4,4 dólares), mientras que el de GPT-5.5 es de 5/30 dólares y el de Opus 4.8 10/50 dólares. Es cierto que consume bastantes más tokens que GPT-5.5 (muy eficiente) o Claude Opus 4.8, pero aun con eso su coste final es muchísimo más bajo.
Mis pruebas con GLM-5.2 programando. Soy suscriptor de Z.ai desde hace meses porque ofrecieron una suscripción anual a finales de 2025 a un precio realmente bajo. Eso me ha permitido probar GLM-5.2 durante unas horas y aunque no puedo sacar conclusiones definitivas, sí parece claro que hay un salto de calidad en cuanto a su capacidad para programar. Le pedí que revisara un proyecto de código personal y detectó varios fallos de seguridad y mejoras posibles de forma muy detallada.
Conversando con GLM5-2. En modo conversacional el comportamiento es mucho más difícil de evaluar: he estado interactuando con el modelo y preguntándole cosas, y aunque sí es mejor que GLM 5.1 muchas veces, otras no lo es tanto y diría que en cuanto a creatividad para redactar los modelos frontera de Google, OpenAI y sobre todo Anthropic siguen siendo bastante superiores. Podéis probarlo en su web, y allí comprobaréis otra cosa: tarda en contestar significativamente más que otros chatbots, porque su fase de razonamiento es más larga. Se toma más tiempo para contestar a las preguntas.
Una cosa son los benchmarks, otra cosa la experiencia. A falta de probarlo (mucho) más, desde luego la impresión es que el modelo ha mejorado de forma sensible ante un GLM-5.1 que se había quedado atrás respecto a sus competidores chinos (no digamos ya los Claude Opus 4.8 o GPT-5.5 de turno). En plataformas como Reddit las opiniones están divididas, pero muchos lo consideran una fantástica opción para correr localmente… si tienes una máquina muy, muy potente con al menos 256 GB de memoria unificada (Mac Studio). Y una cosa parece clara: a la hora de usarlo como un modelo de IA para programar, se acerca de forma sorprendente a Claude Opus 4.8.
–
La noticia
Creíamos que ningún modelo chino de IA se acercaría pronto a Fable 5 o GPT-5.5. Entonces llegó GLM-5.2
fue publicada originalmente en
Xataka
por
Javier Pastor
.
Hace unos días la startup china Zhipu AI (Z.ai) anunció el lanzamiento de su nuevo modelo abierto de IA, GLM-5.2. Lo hizo presumiendo de unas prestaciones asombrosas que lo acercaban mucho a los mejores modelos cerrados de OpenAI y Anthropic, algo que parecía imposible. Pues bien: cuantos más análisis se realizan del modelo, mejor parado queda. Puede que estemos ante el principio de algo muy importante. Un cambio de tendencia.
GLM 5.2. La startup china Z.ai lleva ya mucho tiempo lanzando distitnas versiones de su modelo de IA GLM, pero la última es sin duda la más sorprendente porque su rendimiento es especialmente prometedor. Cuenta con 744.000 millones de parámetros (744B), de los cuales 40.000 son los que se mantienen activos. Estamos ante un modelo con una ventana de contexto de un millón de tokens y una nueva arquitectura llamada IndexShare/IndexCache.
Mejor que GPT-5.5, muy cerca de Opus 4.8. La startup mostró cómo el rendimiento de GLM-5.2 es extraordinario en tareas de programación. En el test FrontierSWE, el más exigente de los existentes actualmente, GLM-5.2 superó a GPT-5.5 y solo Opus 4.8 fue superior por un margen muy pequeño. Lo mismo ocurrió con otras pruebas como PostTrainBench o SWE-Marathon, que por ejemplo evalúa el comportamiento del modelo en larguísimas sesiones de programación autónoma.
Fuente: Z.ai.
En otras muchas pruebas la foto fue idéntica: el modelo ha dado un salto espectacular desde la versión 5.1, y es en muchos tests casi tan bueno (o mejor) como los mejores de OpenAI, Anthropic o Google.
Pero es que no solo lo dicen ellos. Artificial Analysis, una reputada firma independiente que mantiene un ránking actualizado del rendimiento de los nuevos modelos de IA que van llegando al mercado, confirma los datos de la propia Z.ai. En sus pruebas indica cómo el "índice de inteligencia" de GLM-5.2 es ahora de 51 puntos. Solo le superan GPT-5.5 (55), Claude Opus 4.8 (56) y Claude Fable 5 (60).
Fuente: Artificial Analysis.
Este modelo abierto chino deja atrás al nuevo Gemini 3.5 Flash, pero también a competidores chinos como Qwen 3.7 Max, MiniMax-M3 o DeepSeek V4, entre otros. El salto de calidad desde GLM-5.1 es, insistimos, sobresaliente, mucho mayor que el que al menos según este índice se vio desde Opus 4.8 a Fable 5.
El salto de rendimiento es espectacular, aunque es cierto que el precio comparativo para resolver las tareas propuestas en el benchmark sube de forma sensible. Fuente: Artificial Analysis.
Pero no es perfecto. El informe de Artificial Analysis, eso sí, muestra que aunque GLM-5.2 es muy fuerte en ámbitos como la programación, flojea en otros. Por ejemplo, está lejos de ser tan fiable como Fable 5, GPT-5.5, Claude 4.8 o Gemini 3.1 Pro en cuanto a respuestas correctas, que también es menor en proporción a la de sus competidores. Sin embargo ha reducido de forma notable sus alucinaciones.
Y es mucho (muchísimo) más barato. Pero es que además de ser fantástico en muchos ámbitos, es mucho más barato que sus competidores. Mantiene el precio por millón de tokens de entrada/salida de su antecesor (1,4/4,4 dólares), mientras que el de GPT-5.5 es de 5/30 dólares y el de Opus 4.8 10/50 dólares. Es cierto que consume bastantes más tokens que GPT-5.5 (muy eficiente) o Claude Opus 4.8, pero aun con eso su coste final es muchísimo más bajo.
Mis pruebas con GLM-5.2 programando. Soy suscriptor de Z.ai desde hace meses porque ofrecieron una suscripción anual a finales de 2025 a un precio realmente bajo. Eso me ha permitido probar GLM-5.2 durante unas horas y aunque no puedo sacar conclusiones definitivas, sí parece claro que hay un salto de calidad en cuanto a su capacidad para programar. Le pedí que revisara un proyecto de código personal y detectó varios fallos de seguridad y mejoras posibles de forma muy detallada.
Conversando con GLM5-2. En modo conversacional el comportamiento es mucho más difícil de evaluar: he estado interactuando con el modelo y preguntándole cosas, y aunque sí es mejor que GLM 5.1 muchas veces, otras no lo es tanto y diría que en cuanto a creatividad para redactar los modelos frontera de Google, OpenAI y sobre todo Anthropic siguen siendo bastante superiores. Podéis probarlo en su web, y allí comprobaréis otra cosa: tarda en contestar significativamente más que otros chatbots, porque su fase de razonamiento es más larga. Se toma más tiempo para contestar a las preguntas.
Una cosa son los benchmarks, otra cosa la experiencia. A falta de probarlo (mucho) más, desde luego la impresión es que el modelo ha mejorado de forma sensible ante un GLM-5.1 que se había quedado atrás respecto a sus competidores chinos (no digamos ya los Claude Opus 4.8 o GPT-5.5 de turno). En plataformas como Reddit las opiniones están divididas, pero muchos lo consideran una fantástica opción para correr localmente… si tienes una máquina muy, muy potente con al menos 256 GB de memoria unificada (Mac Studio). Y una cosa parece clara: a la hora de usarlo como un modelo de IA para programar, se acerca de forma sorprendente a Claude Opus 4.8.
En Xataka | Las tecnológicas chinas entraron en la carrera IA con modelos más baratos que el resto. Eso está empezando a terminarse
– La noticia
Creíamos que ningún modelo chino de IA se acercaría pronto a Fable 5 o GPT-5.5. Entonces llegó GLM-5.2
fue publicada originalmente en
Xataka
por
Javier Pastor
.





