
Ciencia y Tecnología
Llevamos años buscando bocas de incendio en fotos para demostrar que no somos un robot. Resulta que después de todo éramos el robot
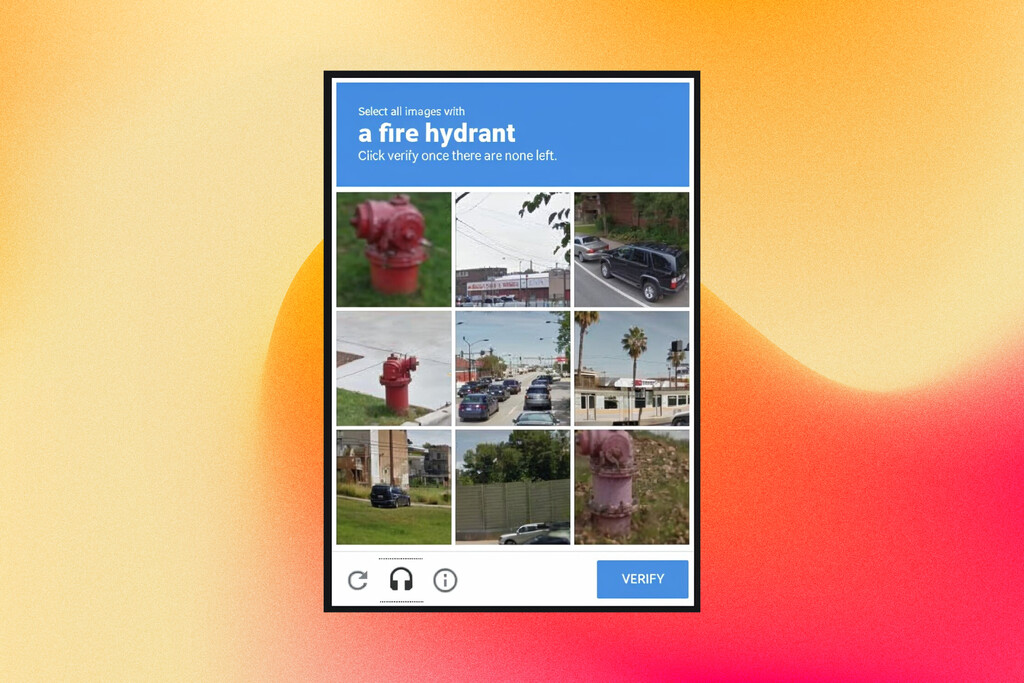
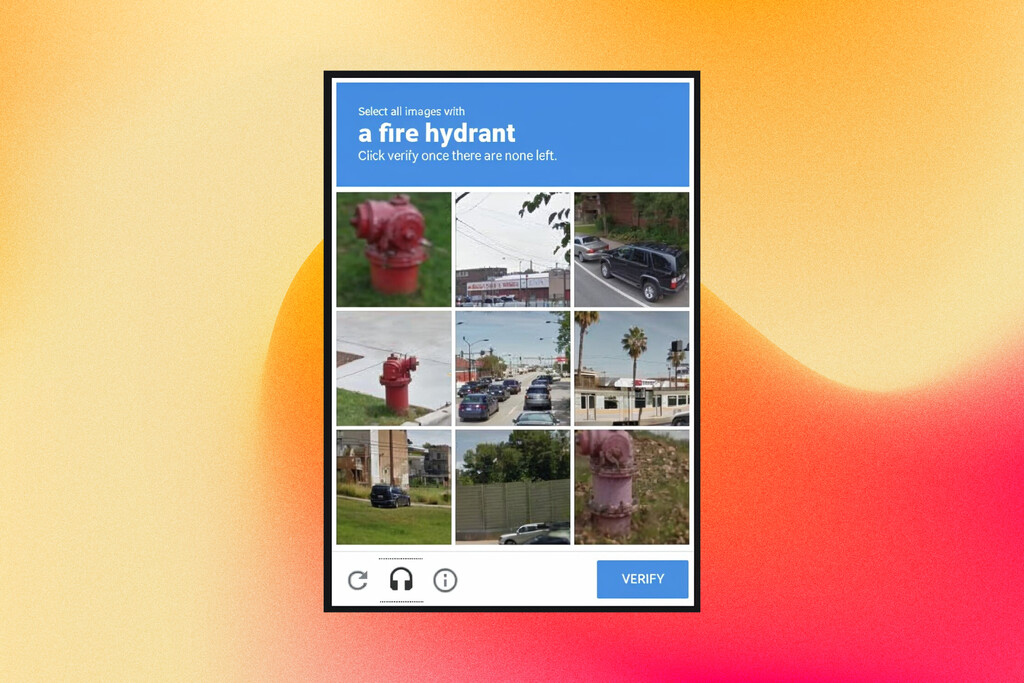
Todos los días nos pasa: intentamos entrar en una web y de repente una cuadrícula de fotos de mala calidad nos exige que identifiquemos todos los semáforos, autobuses o incluso las bocas de incendio aunque en España, por ejemplo, no tengan el característico diseño que se aplica en EEUU. Cuando resolvemos esos puzzles no solo estamos demostrando que no somos un robot: estamos trabajando para Google.
Esclavos de Google. A principios de los 2000 los bots estaban destuyendo internet, pero un joven llamado Luis von Ahn tuvo una idea genial para frenarlos. Creó CAPTCHA, un sistema que nos obligaba a identificar palabras distorsionadas para demostrar que éramos humanos y así poder acceder al contenido. Aquel sistema evolucionó y Google compró la idea y la convirtió en un sistema perfecto para algo que casi ni hemos notado: trabajar para ella.

De Google Maps a Waymo. Desde entonces Google no ha parado de aprovechar el sistema para dos objetivos entrelazados. El primero, efectivamente, protegernos de los bots. El segundo, también conocido pero mucho más jugoso para la empresa, convertirnos a todos en etiquetadores de información. Los usuarios de internet primero reconocimos palabras y nos convertimos en un gigantesco sistema OCR que se aplicó a Google Maps. Luego, con las imágenes, acabamos contribuyendo a que los sistemas de reconocimiento de imágenes de Google mejoraran de forma notable. Eso ha servido entre otras cosas para alimentar los sistemas de conducción autónoma de Waymo.
Consenso estadístico. ¿Cómo sabe Google que cuando elegimos una boca de incendio o un autobús estamos respondiendo correctamente? Lo sabe mediante el llamado "consenso estadístico". Google suele presentar imágenes en parejas: una de ellas (la imagen control) ya ha sido identificada previamente por miles de personas, mientras que la otra es una imagen "huérfana" que sus algoritmos de visión artificial no logran descifrar. Si aciertas la conocida, Google asume que eres humano y utiliza tu respuesta sobre la imagen desconocida para alimentar su base de datos.
Somos el producto. Probablemente todos nuestros lectores ya estábais muy al tanto de esta realidad, pero ahora comienza a activarse un debate sobre la ética y la propiedad del trabajo digital. Es algo que ya vimos con las redes sociales, que se alimentaron de nuestros contenidos, y que desde luego también se aplica a Google: ¿hasta qué punto es lícito que una emprsa tenga una infraestructura enorme de IA gracias a los miles de millones de horas de "microtrabajos" no remunerados de sus usuarios? Aquí resurge el famoso "si no pagas por el producto, eres el producto". Es cierto que estos sistemas de Google nos han protegido de los bots y no hemos pagado por ellos "con dinero"… pero sí con esos microtrabajos que hemos realizado al resolver los puzzles de los sistemas reCAPTACHA.
¿Es posible envenentar el algoritmo? Aquí también surgen dudas sobre la verdadera fiabilidad del sistema. Si un grupo masivo de usuarios decidiera etiquetar erróneamente los semáforos o las bocas de incendios de forma organizada, ¿tomaría un coche autónomo decisiones peligrosas en el mundo real? Ese riesgo parece razonable, y teniendo en cuenta que los modelos de IA son cada vez más capaces en razonamiento abstracto e incluso de superar captchas, un ataque de bots de IA que hiciera algo así plantea una amenaza preocupante.
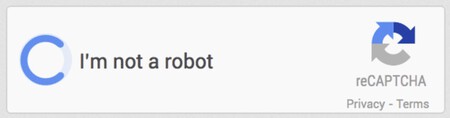
El CAPTCHA invisible. La propia Google sabe que los CAPTCHA visuales ya no son tan infranqueables para las máquinas, así que ha ido desplazando sus sistemas hacia reCAPTCHA v3, un sistema invisible que no requiere que busques autobuses, pasos de cebra o bocas de incendio que nunca verás en una calle de Málaga o de Bilbao. En lugar de eso este sistema analiza de forma opaca tu comportamiento frente al PC: cómo mueves el ratón, qué cookies tienes instaladas y cómo navegas. O lo que es lo mismo: Google cree saber cómo se comporta un humano cuando va a hacer clic en "No soy un robot"… cuando llevamos años trabajando como robots y resolviendo esos puzzles.
Una idea brillante. Lo que está claro es que CAPTCHA ha sido una idea genial con unas implicaciones que ni siquiera Google podría haber anticipado. De hecho, ha convertido esta herramienta en una forma de alimentar sus sistemas de inteligencia artificial con nuestra ayuda, sin que prácticamente nos enteremos (o nos importe mucho). Pero ya sabes: la próxima vez que una web te pida identificar las bocas de incendio antes de entrar en ella, recuerda que no estás demostrando tu humanidad. Estás fichando en el turno de tarde de una de las mayores fábricas de datos del planeta.
–
La noticia
Llevamos años buscando bocas de incendio en fotos para demostrar que no somos un robot. Resulta que después de todo éramos el robot
fue publicada originalmente en
Xataka
por
Javier Pastor
.
Todos los días nos pasa: intentamos entrar en una web y de repente una cuadrícula de fotos de mala calidad nos exige que identifiquemos todos los semáforos, autobuses o incluso las bocas de incendio aunque en España, por ejemplo, no tengan el característico diseño que se aplica en EEUU. Cuando resolvemos esos puzzles no solo estamos demostrando que no somos un robot: estamos trabajando para Google.
Esclavos de Google. A principios de los 2000 los bots estaban destuyendo internet, pero un joven llamado Luis von Ahn tuvo una idea genial para frenarlos. Creó CAPTCHA, un sistema que nos obligaba a identificar palabras distorsionadas para demostrar que éramos humanos y así poder acceder al contenido. Aquel sistema evolucionó y Google compró la idea y la convirtió en un sistema perfecto para algo que casi ni hemos notado: trabajar para ella.
En Xataka
Luis von Ahn, de Duolingo: las certificaciones y las conversaciones llegarán pronto
De Google Maps a Waymo. Desde entonces Google no ha parado de aprovechar el sistema para dos objetivos entrelazados. El primero, efectivamente, protegernos de los bots. El segundo, también conocido pero mucho más jugoso para la empresa, convertirnos a todos en etiquetadores de información. Los usuarios de internet primero reconocimos palabras y nos convertimos en un gigantesco sistema OCR que se aplicó a Google Maps. Luego, con las imágenes, acabamos contribuyendo a que los sistemas de reconocimiento de imágenes de Google mejoraran de forma notable. Eso ha servido entre otras cosas para alimentar los sistemas de conducción autónoma de Waymo.
Consenso estadístico. ¿Cómo sabe Google que cuando elegimos una boca de incendio o un autobús estamos respondiendo correctamente? Lo sabe mediante el llamado "consenso estadístico". Google suele presentar imágenes en parejas: una de ellas (la imagen control) ya ha sido identificada previamente por miles de personas, mientras que la otra es una imagen "huérfana" que sus algoritmos de visión artificial no logran descifrar. Si aciertas la conocida, Google asume que eres humano y utiliza tu respuesta sobre la imagen desconocida para alimentar su base de datos.
Somos el producto. Probablemente todos nuestros lectores ya estábais muy al tanto de esta realidad, pero ahora comienza a activarse un debate sobre la ética y la propiedad del trabajo digital. Es algo que ya vimos con las redes sociales, que se alimentaron de nuestros contenidos, y que desde luego también se aplica a Google: ¿hasta qué punto es lícito que una emprsa tenga una infraestructura enorme de IA gracias a los miles de millones de horas de "microtrabajos" no remunerados de sus usuarios? Aquí resurge el famoso "si no pagas por el producto, eres el producto". Es cierto que estos sistemas de Google nos han protegido de los bots y no hemos pagado por ellos "con dinero"… pero sí con esos microtrabajos que hemos realizado al resolver los puzzles de los sistemas reCAPTACHA.
¿Es posible envenentar el algoritmo? Aquí también surgen dudas sobre la verdadera fiabilidad del sistema. Si un grupo masivo de usuarios decidiera etiquetar erróneamente los semáforos o las bocas de incendios de forma organizada, ¿tomaría un coche autónomo decisiones peligrosas en el mundo real? Ese riesgo parece razonable, y teniendo en cuenta que los modelos de IA son cada vez más capaces en razonamiento abstracto e incluso de superar captchas, un ataque de bots de IA que hiciera algo así plantea una amenaza preocupante.
El CAPTCHA invisible. La propia Google sabe que los CAPTCHA visuales ya no son tan infranqueables para las máquinas, así que ha ido desplazando sus sistemas hacia reCAPTCHA v3, un sistema invisible que no requiere que busques autobuses, pasos de cebra o bocas de incendio que nunca verás en una calle de Málaga o de Bilbao. En lugar de eso este sistema analiza de forma opaca tu comportamiento frente al PC: cómo mueves el ratón, qué cookies tienes instaladas y cómo navegas. O lo que es lo mismo: Google cree saber cómo se comporta un humano cuando va a hacer clic en "No soy un robot"… cuando llevamos años trabajando como robots y resolviendo esos puzzles.
Una idea brillante. Lo que está claro es que CAPTCHA ha sido una idea genial con unas implicaciones que ni siquiera Google podría haber anticipado. De hecho, ha convertido esta herramienta en una forma de alimentar sus sistemas de inteligencia artificial con nuestra ayuda, sin que prácticamente nos enteremos (o nos importe mucho). Pero ya sabes: la próxima vez que una web te pida identificar las bocas de incendio antes de entrar en ella, recuerda que no estás demostrando tu humanidad. Estás fichando en el turno de tarde de una de las mayores fábricas de datos del planeta.
En Xataka | EEUU bloqueó sus chips más avanzados a China para frenar su IA. El resultado: China fabrica tokens más baratos que nadie
– La noticia
Llevamos años buscando bocas de incendio en fotos para demostrar que no somos un robot. Resulta que después de todo éramos el robot
fue publicada originalmente en
Xataka
por
Javier Pastor
.




