

Ciencia y Tecnología
El arranque de ALIA, el modelo de IA español, ha sido errático y decepcionante. Ahora sabemos por qué


Empecemos por lo importante. ALIA, el modelo de IA español, no tenía que haberse lanzado cuando se lanzó.
En Xataka hemos hablado con uno de los principales responsables de su desarrollo y eso nos ha permitido conocer y entender mucho mejor su alcance y sus objetivos, pero también por qué la (inevitable) comparación con ChatGPT no solo es injusta: es inapropiada.
ALIA-40b es un modelo fundacional de IA, esto es, un modelo de inteligencia artificial de gran escala entrenado con una cantidad masiva y diversa de datos, y que sirve como base para multitud de aplicaciones distintas. Este proyecto está coordinado por el Barcelona Supercomputing Center (BSC-CNS), y aunque se ha podido beneficiar de la infraestructura del supercomputador MareNostrum 5, incluso esa ventaja ha sido limitada.

Como decimos, comparar el rendimiento de ALIA-40b con el de modelos como GPT-5 o Gemini 3 es inapropiado, y para entenderlo todo mejor hay que entender de dónde parte el proyecto, qué objetivos tiene y cómo su desarrollo es mucho más modesto —y aun así prometedor— que el de los grandes modelos propietarios de EEUU y también el de los llamativos modelos abiertos que están apareciendo en China. Conozcamos más de cerca qué pasó con ALIA… y qué esperamos que pase.
Promesas y realidades
Aquel 20 de enero de 2025, Pedro Sánchez, presidente del Gobierno de España, anunciaba el lanzamiento de ALIA y todo parecía sonar bien. Ya había avisado casi un año antes de esta iniciativa, aunque entonces apenas dio detalles. Se habló de la familia de modelos de IA en castellano y lenguas cooficiales “pensados para fomentar la investigación en este campo y desarrollar soluciones tecnológicas en castellano, el cuarto idioma más hablado del mundo y el segundo más usado en Internet”.

Incluso se mencionó que ya estaban en marcha proyectos para aplicar ALIA en dos proyectos piloto para la Agencia Tributaria y para una aplicación en la medicina de atención primaria. En la web del BSC-CNS se aportaron algunos detalles técnicos: ALIA-40b era, según los responsables de dicho organismo:
“El modelo fundacional multilingüe público más avanzado de Europa con 40.000 millones de parámetros, que ha sido entrenado durante más de 8 meses en el MareNostrum 5 con 6,9 billones de tokens (palabras o fragmentos de palabras usadas en estos sistemas) en 35 lenguas europeas. Su versión final estará entrenada con hasta 9,2 billones de tokens”.
La realidad era algo distinta. De hecho, ALIA-40b fue criticado entre quienes lo probaron. Las pruebas de rendimiento iniciales ya mostraron cómo el rendimiento era muy pobre y comparable al de Llama-2-34b, un modelo Open Source que se lanzó a mediados de 2023.
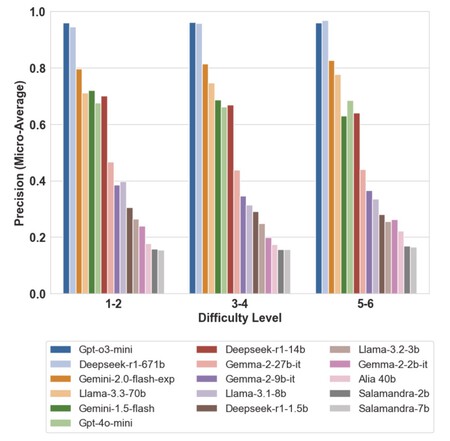
En el estudio de la UPV se puede ver como ALIA-40b, Salamandra-2b y Salamandra-7b fueron de lejos los peores en las pruebas realizadas.
Un estudio posterior de investigadores de la Universidad de Valencia puso a prueba esa capacidad y sus conclusiones fueron claras. En exámenes de matemáticas tipo test puntuó peor que el resto de LLMs, e incluso puntuó peor que si hubiera tratado de adivinar las respuestas.
El mensaje fue claro: ALIA estaba muy por detrás de sus competidores. El modelo ni siquiera forma parte de grandes comparativas de rendimiento como las de LLM-Stats, Artificial Analysis y sobre todo LMArena que entre sus 176 modelos no incluye el modelo español.
Un lanzamiento prematuro
Hay una razón sencilla para ese comportamiento: ALIA ni siquiera estaba preparado para esas pruebas, y no lo estaba porque se lanzó de forma prematura. Nos lo explica Aitor González-Agirre, uno de los responsables del desarrollo de ALIA en en BSC.

Él destaca que aquel lanzamiento “no fue una decisión técnica”. A la hora de entrenar ALIA el equipo se encontró con un problema clásico: tuvieron que interrumpir un proceso diseñado para ser largo mucho antes de tiempo.
En el entrenamiento de modelos de IA hay un concepto llamado tasa de aprendizaje que indica la “velocidad” a la que el modelo aprende. Al principio quieres una tasa alta para aprender “rápido” y absorber conceptos generales, pero al final quieres una tasa muy baja que permita pulir detalles finos y asentar ese conocimiento sin romper lo aprendido.
Para realizar ese entrenamiento se utiliza un planificador (scheduler) que le dice a la máquina —en este caso, MareNostrum 5— cómo ir cambiando esa velocidad a lo largo del tiempo, y aquí se usó un scheduler basado en coseno: empieza en un pico alto, baja suavemente al principio, pero luego baja más rápidamente en el medio para aterrizar muy suavamente al final.
González-Agirre indica que con ALIA tenían la intención de entrenar “con 12 billones de tokens (12T)”, pero la realidad es que por decisiones estratégicas pero no técnicas tuvieron que parar.
“Sabíamos que no se iba a poder hacer”, añade. Aunque tuvieron acceso a MareNostrum 5 para hacer pruebas iniciales, tuvieron que lanzar el modelo cuando solo llevaban 2,3 billones de tokens. El scheduler aun estaba en fase de velocidad alta, no había llegado a esa fase final de refinamiento, y básicamente el modelo no estaba básicamente “crudo”.

La descripción de ALIA-40b en Hugging Face muestra una advertencia clara del estado del modelo, que no cuenta aún con instrucciones ni alineamiento, y que por tanto puede generar salidas inapropiadas, incorrectas o incluso inseguras. Sigue siendo un modelo “crudo” en pleno desarrollo, y hay que tomarlo como tal.
Hubo un problema adicional, indica este experto. ALIA-40B “se lanzó como modelo preentrenado. No tenía instrucciones ni alineamiento ni nada. El modelo no era un producto final, no era ese el objetivo”. Para mucha gente ALIA-40b simplemente a esas alturas debía poder contestar a nuestras preguntas de forma más o menos coherente, pero no lo hacía, y ahí entran esas diferencias tan claras de esas “capas” del proceso de desarrollo de un modelo de IA:
- Modelo preentrenado (pre-trained, la base bruta): sabe predecir qué palabra viene después de otra, pero no sabe charlar ni obedecer. No es capaz de saber si le estás haciendo una pregunta, y solo intenta adivinar el texto que viene a continuación. Las respuestas, por tanto, pueden ser totalmente incoherentes con lo que nosotros pretendíamos preguntar. Es un modelo “crudo”, casi “salvaje”.
- Instrucciones (Instruction Tuning): al modelo crudo se le entrena con ejemplos específicos de pregunta-respuesta y se le enseña al modelo a ejecutar ciertas acciones. Cuando al modelo preentrenado le dices “La capital de Francia es… “él puede completar con “… una ciudad bonita”. Pero el modelo con instrucciones (a menudo llevan el “apellido” Instruct en su nombre) le enseñas que debe responder “… París”.
- Alineamiento (Alignment): en esta capa se le añade seguridad y estilo al modelo y a menudo se aplica aprendizaje por refuerzo por retroalimentación humana. Aquí el modelo aprende que no debe contestar ciertas preguntas (de ahí respuestas del tpo “No puedo ayudarte con eso” cuando pedimos a un modelo que nos ayude a crear una bomba), y también a no ser grosero o racista, por ejemplo.
ALIA-40b ni siquiera había completado su fase inicial de entrenamiento cuando se presentó, y eso hizo que aquella versión inicial no estuviese preparada para salir a escena: “solo era un modelo que completaba texto” pero simplemente lo hacía de formas que no eran las que esperábamos. Aquel desconocimiento de las condiciones en las que salió provocó cierta decepción, y a esa sensación se unió otro fenómeno: el provocado por DeepSeek.

Meses después esa fase inicial sí está completada, y González-Agirre indica que el comportamiento actual del modelo es mucho mejor. Al compararlo con el modelo suizo Apertus-8b, y con variantes de Qwen y Llama-3 afirma que “es el mejor de los modelos en euskera, y el segundo en catalán y gallego”. De hecho la ventana de contexto del modelo actual se ha ampliado a 160K tokens (160.000), cuando inicialmente se le criticó mucho que fuera de tan solo 4K, pero como dice este ingeniero “no se podía entrenar para más” en aquel momento.
Un camino plagado de obstáculos
A partir de aquí el camino se allana un poco, y según este experto para final de año quieren “tener un modelo que tenga instrucciones y que responda como nosotros queremos”, pero aquí se enfrentan a obstáculos importantes.
Probablemente uno de los más importantes está en el conjunto de datos al que pueden acceder para entrenar el modelo. Aquí González-Agirre explica la dicotomía:
“Hay muchas cosas que mejorar, pero también muchas restricciones de conjuntos de datos (datasets) que tenemos que respetar. Si eres una tecnológica con más abogados que Disney puedes hacer otras cosas, pero nosotros no usamos datos con copyright y tampoco usamos datos generados por Llama o GPT o por modelos que no permiten usar sus salidas”.
De hecho, entre los conjuntos de datos utilizados para entrenar ALIA estaba Common Crawl, un repositorio en el que hay todo tipo de contenidos de internet que se usan sin pagar licencias. Fuentes citadas en El País indicaron recientemente que ese entrenamiento se amparó en la normativa vigente y “en una serie de excepciones para hacer minería de datos”. Los autores pueden prohibir que se usen sus obras, pero deben seguir “un complejo proceso” para evitarlo.
En el desarrollo de ALIA tienen muy en cuenta esos requisitos y de hecho tienen que regenerar esos conjuntos de datos para evitar que se incumplan cualquiera de los términos especificados.
El mundo ya ha asumido que los modelos de IA han saqueado internet para su entrenamiento, y casi siempre sin pedir permiso o sin pagar por los contenidos con los que se han entrenado. Eso ha dado lugar a un sinfín de demandas, y también ha hecho que algunas empresas de IA lleguen a acuerdos extrajudiciales con los poseedores de esos derechos. Es lo que pasó hace unos meses con Anthropic, que firmó uno de esos acuerdos con un grupo de autores, a los que pagará unos 1.500 millones de dólares. Otras han seguido ese camino, pero no desde luego el desarrollo del BSC-CNS, que se enfrentó a otra dificultad: la capacidad de cómputo disponible.

Dicho acceso se ha ido reduciendo de forma notable con el tiempo. Marta Villegas, del equipo de desarrollo de ALIA, ya nos habló de ello en nuestra entrevista en enero. Aunque durante un breve espacio de tiempo tuvieron acceso a 512 de los 1.120 nodos especializados del supercomputador, se usaron 256 nodos durante bastantes meses y desde septiembre están usando 128 nodos, “que son muchos”.
Esa cifra ahora se ha reducido a 16 nodos dedicados, lo que impide hacer pretraining. Aun así, explica, “también es cierto que en estos momentos estamos trabajando en una parte menos intensiva”, pero esa limitación inicial también hacía imposible compararse con otros gigantes: “Con ChatGPT hicieron centenares de versiones distintas y se quedaron con la buena”, pero ALIA solo se pudo entrenar una vez.
Hay otro problemón importante para que ALIA pueda avanzar, y es que como explica González-Agirre, “no tenemos inferencia”. Es decir, no hay una app o un sitio web o plataforma tipo chat.alia.es que permita probar el modelo de IA en directo, como ocurre con ChatGPT, Gemini, Claude o cualquiera de sus competidores, incluso de modelos (relativamente) abiertos como Mistral.
“Quien no tenga coche, que al menos pueda ir en autobús”
Ese es otro obstáculo más porque, destaca nuestro protagonista, “no tenemos datos de los prompts que está usando la gente, de cómo usa el modelo, de esos pulgares hacia arriba y hacia abajo”.
En Hugging Face se puede consultar cómo las actualizaciones son frecuentes en este proyecto: aparecen nuevos modelos cada pocas semanas… o días.
Esa infrmación le da muchas pistas a las grandes tecnológicas de si sus modelos están cumpliendo con las expectativas de los usuarios o no. Aquí añadía además algo importante:
“Hay opciones de tener inferencia y centros de datos. Están Jupiter, Leonardo o Lumi, por ejemplo, pero falta voluntad política. Esto es una alternativa pública, la necesitamos y no podemos dejar algo así en manos privadas”.
Para él que existan modelos comerciales y cerrados es normal y totalmente respetable, pero la analogía en su opinión es clara. Esto es como los coches privados y los autobuses: “quien no tenga coche, que al menos pueda ir en autobús”. Esa es sin duda la razón de ser de un modelo que no pretende competir con ChatGPT o Gemini. González-Agirre señala que
“Lo que pretendemos es que sea bueno en los idiomas cooficiales, que sea mejor que otros modelos, y lo siguiente es que esté alineado con nuestros valores y cultura. Que no sea un modelo de otro idioma hablando español. Que no pase como en los modelos chinos, que no pueden contestar algunas cosas. Que podamos defender que no tiene sesgos ni de género, ni de raza, ni de edad, y que haya trazabilidad y transparencia completa”.
Y aquí también destaca que en su equipo y en España “hay gente muy, muy buena, y que aprende mucho, pero me gustaría que esta gente tuviera recursos para quedarse aquí y contribuyese al tejido de España y Europa”.

ALIA se enfrenta también a una competencia feroz por parte de los modelos (más o menos) abiertos que llegan de China, y aunque González-Agirre admite que “tienen unos modelos muy buenos y eficientes, pero no tan baratos como ellos dicen”, añade que “prefiero usar un modelo soberano que sé cómo está hecho”. En ALIA la transparencia es completa, y además hacen uso de una licencia Apache que precisamente defiende ese enfoque abierto.
El futuro inmediato de estos modelos es prometedor. “A finales de año tendremos versiones muy usables del modelo con un rendimiento parecido a modelos de su tamaño”, pero tendrán que trabajar también con su equipo Red Team —que intenta hacer “jailbreak” de ALIA para evitar que genere cosas que no debe.
A partir de ahí, el objetivo es el de lograr versiones de ALIA que tengan capacidades de razonamiento, agénticas y que también sea capaz de realizar llamadas a herramientas, como algunos de sus competidores comerciales. El camino será probablemente mucho más difícil que el de las grandes empresas que no paran de lanzar novedades sin pedir ni permiso ni perdón, pero el resultado, esperemos, valdrá la pena.
–
La noticia
El arranque de ALIA, el modelo de IA español, ha sido errático y decepcionante. Ahora sabemos por qué
fue publicada originalmente en
Xataka
por
Javier Pastor
.
Empecemos por lo importante. ALIA, el modelo de IA español, no tenía que haberse lanzado cuando se lanzó.
En Xataka hemos hablado con uno de los principales responsables de su desarrollo y eso nos ha permitido conocer y entender mucho mejor su alcance y sus objetivos, pero también por qué la (inevitable) comparación con ChatGPT no solo es injusta: es inapropiada.
ALIA-40b es un modelo fundacional de IA, esto es, un modelo de inteligencia artificial de gran escala entrenado con una cantidad masiva y diversa de datos, y que sirve como base para multitud de aplicaciones distintas. Este proyecto está coordinado por el Barcelona Supercomputing Center (BSC-CNS), y aunque se ha podido beneficiar de la infraestructura del supercomputador MareNostrum 5, incluso esa ventaja ha sido limitada.
En Xataka
“El objetivo no es competir con ChatGPT”: hablamos con los creadores de ALIA, la IA 100% española, para entender su futuro
Como decimos, comparar el rendimiento de ALIA-40b con el de modelos como GPT-5 o Gemini 3 es inapropiado, y para entenderlo todo mejor hay que entender de dónde parte el proyecto, qué objetivos tiene y cómo su desarrollo es mucho más modesto —y aun así prometedor— que el de los grandes modelos propietarios de EEUU y también el de los llamativos modelos abiertos que están apareciendo en China. Conozcamos más de cerca qué pasó con ALIA… y qué esperamos que pase.
Promesas y realidadesAquel 20 de enero de 2025, Pedro Sánchez, presidente del Gobierno de España, anunciaba el lanzamiento de ALIA y todo parecía sonar bien. Ya había avisado casi un año antes de esta iniciativa, aunque entonces apenas dio detalles. Se habló de la familia de modelos de IA en castellano y lenguas cooficiales “pensados para fomentar la investigación en este campo y desarrollar soluciones tecnológicas en castellano, el cuarto idioma más hablado del mundo y el segundo más usado en Internet”.
En Xataka
Una IA “nacional” que simplifique los trámites burocráticos es una excelente idea. El problema es si España puede implementarla
Incluso se mencionó que ya estaban en marcha proyectos para aplicar ALIA en dos proyectos piloto para la Agencia Tributaria y para una aplicación en la medicina de atención primaria. En la web del BSC-CNS se aportaron algunos detalles técnicos: ALIA-40b era, según los responsables de dicho organismo:
“El modelo fundacional multilingüe público más avanzado de Europa con 40.000 millones de parámetros, que ha sido entrenado durante más de 8 meses en el MareNostrum 5 con 6,9 billones de tokens (palabras o fragmentos de palabras usadas en estos sistemas) en 35 lenguas europeas. Su versión final estará entrenada con hasta 9,2 billones de tokens”.
La realidad era algo distinta. De hecho, ALIA-40b fue criticado entre quienes lo probaron. Las pruebas de rendimiento iniciales ya mostraron cómo el rendimiento era muy pobre y comparable al de Llama-2-34b, un modelo Open Source que se lanzó a mediados de 2023.
En el estudio de la UPV se puede ver como ALIA-40b, Salamandra-2b y Salamandra-7b fueron de lejos los peores en las pruebas realizadas.
Un estudio posterior de investigadores de la Universidad de Valencia puso a prueba esa capacidad y sus conclusiones fueron claras. En exámenes de matemáticas tipo test puntuó peor que el resto de LLMs, e incluso puntuó peor que si hubiera tratado de adivinar las respuestas.
El mensaje fue claro: ALIA estaba muy por detrás de sus competidores. El modelo ni siquiera forma parte de grandes comparativas de rendimiento como las de LLM-Stats, Artificial Analysis y sobre todo LMArena que entre sus 176 modelos no incluye el modelo español.
Un lanzamiento prematuroHay una razón sencilla para ese comportamiento: ALIA ni siquiera estaba preparado para esas pruebas, y no lo estaba porque se lanzó de forma prematura. Nos lo explica Aitor González-Agirre, uno de los responsables del desarrollo de ALIA en en BSC.
Él destaca que aquel lanzamiento “no fue una decisión técnica”. A la hora de entrenar ALIA el equipo se encontró con un problema clásico: tuvieron que interrumpir un proceso diseñado para ser largo mucho antes de tiempo.
En el entrenamiento de modelos de IA hay un concepto llamado tasa de aprendizaje que indica la “velocidad” a la que el modelo aprende. Al principio quieres una tasa alta para aprender “rápido” y absorber conceptos generales, pero al final quieres una tasa muy baja que permita pulir detalles finos y asentar ese conocimiento sin romper lo aprendido.
Para realizar ese entrenamiento se utiliza un planificador (scheduler) que le dice a la máquina —en este caso, MareNostrum 5— cómo ir cambiando esa velocidad a lo largo del tiempo, y aquí se usó un scheduler basado en coseno: empieza en un pico alto, baja suavemente al principio, pero luego baja más rápidamente en el medio para aterrizar muy suavamente al final.
González-Agirre indica que con ALIA tenían la intención de entrenar “con 12 billones de tokens (12T)”, pero la realidad es que por decisiones estratégicas pero no técnicas tuvieron que parar.
“Sabíamos que no se iba a poder hacer”, añade. Aunque tuvieron acceso a MareNostrum 5 para hacer pruebas iniciales, tuvieron que lanzar el modelo cuando solo llevaban 2,3 billones de tokens. El scheduler aun estaba en fase de velocidad alta, no había llegado a esa fase final de refinamiento, y básicamente el modelo no estaba básicamente “crudo”.
La descripción de ALIA-40b en Hugging Face muestra una advertencia clara del estado del modelo, que no cuenta aún con instrucciones ni alineamiento, y que por tanto puede generar salidas inapropiadas, incorrectas o incluso inseguras. Sigue siendo un modelo “crudo” en pleno desarrollo, y hay que tomarlo como tal.
Hubo un problema adicional, indica este experto. ALIA-40B “se lanzó como modelo preentrenado. No tenía instrucciones ni alineamiento ni nada. El modelo no era un producto final, no era ese el objetivo”. Para mucha gente ALIA-40b simplemente a esas alturas debía poder contestar a nuestras preguntas de forma más o menos coherente, pero no lo hacía, y ahí entran esas diferencias tan claras de esas “capas” del proceso de desarrollo de un modelo de IA:
Modelo preentrenado (pre-trained, la base bruta): sabe predecir qué palabra viene después de otra, pero no sabe charlar ni obedecer. No es capaz de saber si le estás haciendo una pregunta, y solo intenta adivinar el texto que viene a continuación. Las respuestas, por tanto, pueden ser totalmente incoherentes con lo que nosotros pretendíamos preguntar. Es un modelo “crudo”, casi “salvaje”. Instrucciones (Instruction Tuning): al modelo crudo se le entrena con ejemplos específicos de pregunta-respuesta y se le enseña al modelo a ejecutar ciertas acciones. Cuando al modelo preentrenado le dices “La capital de Francia es… “él puede completar con “… una ciudad bonita”. Pero el modelo con instrucciones (a menudo llevan el “apellido” Instruct en su nombre) le enseñas que debe responder “… París”.Alineamiento (Alignment): en esta capa se le añade seguridad y estilo al modelo y a menudo se aplica aprendizaje por refuerzo por retroalimentación humana. Aquí el modelo aprende que no debe contestar ciertas preguntas (de ahí respuestas del tpo “No puedo ayudarte con eso” cuando pedimos a un modelo que nos ayude a crear una bomba), y también a no ser grosero o racista, por ejemplo.
ALIA-40b ni siquiera había completado su fase inicial de entrenamiento cuando se presentó, y eso hizo que aquella versión inicial no estuviese preparada para salir a escena: “solo era un modelo que completaba texto” pero simplemente lo hacía de formas que no eran las que esperábamos. Aquel desconocimiento de las condiciones en las que salió provocó cierta decepción, y a esa sensación se unió otro fenómeno: el provocado por DeepSeek.
En Xataka
España quiere su Hugging Face. Llega justo cuando la fiesta ya casi ha terminado
Meses después esa fase inicial sí está completada, y González-Agirre indica que el comportamiento actual del modelo es mucho mejor. Al compararlo con el modelo suizo Apertus-8b, y con variantes de Qwen y Llama-3 afirma que “es el mejor de los modelos en euskera, y el segundo en catalán y gallego”. De hecho la ventana de contexto del modelo actual se ha ampliado a 160K tokens (160.000), cuando inicialmente se le criticó mucho que fuera de tan solo 4K, pero como dice este ingeniero “no se podía entrenar para más” en aquel momento.
Un camino plagado de obstáculos
A partir de aquí el camino se allana un poco, y según este experto para final de año quieren “tener un modelo que tenga instrucciones y que responda como nosotros queremos”, pero aquí se enfrentan a obstáculos importantes.
Probablemente uno de los más importantes está en el conjunto de datos al que pueden acceder para entrenar el modelo. Aquí González-Agirre explica la dicotomía:
“Hay muchas cosas que mejorar, pero también muchas restricciones de conjuntos de datos (datasets) que tenemos que respetar. Si eres una tecnológica con más abogados que Disney puedes hacer otras cosas, pero nosotros no usamos datos con copyright y tampoco usamos datos generados por Llama o GPT o por modelos que no permiten usar sus salidas”.De hecho, entre los conjuntos de datos utilizados para entrenar ALIA estaba Common Crawl, un repositorio en el que hay todo tipo de contenidos de internet que se usan sin pagar licencias. Fuentes citadas en El País indicaron recientemente que ese entrenamiento se amparó en la normativa vigente y “en una serie de excepciones para hacer minería de datos”. Los autores pueden prohibir que se usen sus obras, pero deben seguir “un complejo proceso” para evitarlo.
En el desarrollo de ALIA tienen muy en cuenta esos requisitos y de hecho tienen que regenerar esos conjuntos de datos para evitar que se incumplan cualquiera de los términos especificados.
El mundo ya ha asumido que los modelos de IA han saqueado internet para su entrenamiento, y casi siempre sin pedir permiso o sin pagar por los contenidos con los que se han entrenado. Eso ha dado lugar a un sinfín de demandas, y también ha hecho que algunas empresas de IA lleguen a acuerdos extrajudiciales con los poseedores de esos derechos. Es lo que pasó hace unos meses con Anthropic, que firmó uno de esos acuerdos con un grupo de autores, a los que pagará unos 1.500 millones de dólares. Otras han seguido ese camino, pero no desde luego el desarrollo del BSC-CNS, que se enfrentó a otra dificultad: la capacidad de cómputo disponible.
En Xataka
En Europa tenemos un problema: nos estamos convirtiendo en la Japón del siglo XXI
Dicho acceso se ha ido reduciendo de forma notable con el tiempo. Marta Villegas, del equipo de desarrollo de ALIA, ya nos habló de ello en nuestra entrevista en enero. Aunque durante un breve espacio de tiempo tuvieron acceso a 512 de los 1.120 nodos especializados del supercomputador, se usaron 256 nodos durante bastantes meses y desde septiembre están usando 128 nodos, “que son muchos”.
Esa cifra ahora se ha reducido a 16 nodos dedicados, lo que impide hacer pretraining. Aun así, explica, “también es cierto que en estos momentos estamos trabajando en una parte menos intensiva”, pero esa limitación inicial también hacía imposible compararse con otros gigantes: “Con ChatGPT hicieron centenares de versiones distintas y se quedaron con la buena”, pero ALIA solo se pudo entrenar una vez.
Hay otro problemón importante para que ALIA pueda avanzar, y es que como explica González-Agirre, “no tenemos inferencia”. Es decir, no hay una app o un sitio web o plataforma tipo chat.alia.es que permita probar el modelo de IA en directo, como ocurre con ChatGPT, Gemini, Claude o cualquiera de sus competidores, incluso de modelos (relativamente) abiertos como Mistral.
“Quien no tenga coche, que al menos pueda ir en autobús”Ese es otro obstáculo más porque, destaca nuestro protagonista, “no tenemos datos de los prompts que está usando la gente, de cómo usa el modelo, de esos pulgares hacia arriba y hacia abajo”.
En Hugging Face se puede consultar cómo las actualizaciones son frecuentes en este proyecto: aparecen nuevos modelos cada pocas semanas… o días.
Esa infrmación le da muchas pistas a las grandes tecnológicas de si sus modelos están cumpliendo con las expectativas de los usuarios o no. Aquí añadía además algo importante:
“Hay opciones de tener inferencia y centros de datos. Están Jupiter, Leonardo o Lumi, por ejemplo, pero falta voluntad política. Esto es una alternativa pública, la necesitamos y no podemos dejar algo así en manos privadas”. Para él que existan modelos comerciales y cerrados es normal y totalmente respetable, pero la analogía en su opinión es clara. Esto es como los coches privados y los autobuses: “quien no tenga coche, que al menos pueda ir en autobús”. Esa es sin duda la razón de ser de un modelo que no pretende competir con ChatGPT o Gemini. González-Agirre señala que
“Lo que pretendemos es que sea bueno en los idiomas cooficiales, que sea mejor que otros modelos, y lo siguiente es que esté alineado con nuestros valores y cultura. Que no sea un modelo de otro idioma hablando español. Que no pase como en los modelos chinos, que no pueden contestar algunas cosas. Que podamos defender que no tiene sesgos ni de género, ni de raza, ni de edad, y que haya trazabilidad y transparencia completa”.Y aquí también destaca que en su equipo y en España “hay gente muy, muy buena, y que aprende mucho, pero me gustaría que esta gente tuviera recursos para quedarse aquí y contribuyese al tejido de España y Europa”.
En Xataka
España no es en absoluto puntera en IA, pero ya tenemos una agencia regulatoria con 80 empleados. No sabemos muy bien qué van a regular
ALIA se enfrenta también a una competencia feroz por parte de los modelos (más o menos) abiertos que llegan de China, y aunque González-Agirre admite que “tienen unos modelos muy buenos y eficientes, pero no tan baratos como ellos dicen”, añade que “prefiero usar un modelo soberano que sé cómo está hecho”. En ALIA la transparencia es completa, y además hacen uso de una licencia Apache que precisamente defiende ese enfoque abierto.
El futuro inmediato de estos modelos es prometedor. “A finales de año tendremos versiones muy usables del modelo con un rendimiento parecido a modelos de su tamaño”, pero tendrán que trabajar también con su equipo Red Team —que intenta hacer “jailbreak” de ALIA para evitar que genere cosas que no debe.
A partir de ahí, el objetivo es el de lograr versiones de ALIA que tengan capacidades de razonamiento, agénticas y que también sea capaz de realizar llamadas a herramientas, como algunos de sus competidores comerciales. El camino será probablemente mucho más difícil que el de las grandes empresas que no paran de lanzar novedades sin pedir ni permiso ni perdón, pero el resultado, esperemos, valdrá la pena.
En Xataka | España ha firmado un acuerdo con IBM para chatbots de IA en euskera, gallego y catalán. El problema es que ya existen
– La noticia
El arranque de ALIA, el modelo de IA español, ha sido errático y decepcionante. Ahora sabemos por qué
fue publicada originalmente en
Xataka
por
Javier Pastor
.











