

Ciencia y Tecnología
Tenemos un nuevo ganador en generación de imágenes con IA. Y no es estadounidense, sino chino


Tencent acaba de lanzar un nuevo modelo de IA capaz de generar imágenes a partir de un prompt de texto. Tradicionalmente los modelos propietarios han dominado este tipo de tarea creativa, pero el modelo de Tencent ha dado la sorpresa y según diversos benchmarks es capaz de generar imágenes mejor que el resto de competidores, incluidos los de Google y OpenAI.
Hunyuan Image 3.0. Así se llama el nuevo modelo de Tencent, que en la clasificación de LMArena de modelos más potentes para la generación de imágenes a partir de texto ha logrado superar a Gemini 2.5 Flash Image Preview (popularmente conocido como nano banana), además de a otros modelos propietarios como GPT-Image-1, Flux-1-Kontext-Max o Qwen-Image.
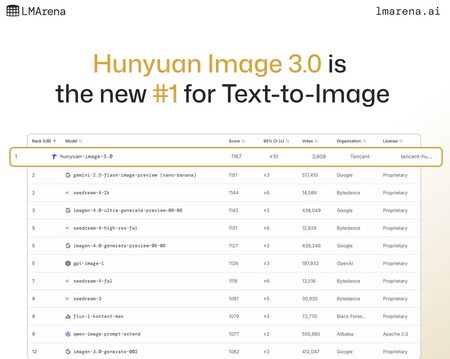
El modelo de imagen de Tencent ha logrado ya superar a sus competidores según los expertos de LM Arena.
Votación a ciegas. Esa clasificación de LM Arena funciona mediante un sistema de votación ciega en el cual losusuarios eligen sus imágenes preferidas sin saber qué modelo los generó. Y según dicha votación, este modelo de Tencent superó a todos sus contrincantes, incluyendo al popular “nano banana” de Google. Eso sí: la votación también tiene en cuenta resultados a largo plazo, y el corto periodo que lleva disponible Hunyuan Image 3.0 hace que los resultados se califiquen como “preliminares” y no definitivos.
Cómo funciona. Los responsables de Tencent explican en la descripción del modelo cómo han utilizado una nueva arquitectura de difusión que hace uso de codificadores duales (un LLM multimodal y otro que entiende mejor los caracteres de distintos idiomas) y optimización RLHF (Reinforcement Learning from Human Feedback, que refina el resultado previo) para la creación de imágenes de mayor calidad. El sistema hace uso además de un sistema de compresión para que todo el proceso consuma menos recursos sin pérdida de calidad.

Pesos abiertos y licencia comercial. Hunyuan Image 3.0 es un modelo que comparte su código en GitHub y que ofrece una licencia sorprendentemente permisiva. De hecho es posible hasta usarlo con fines comerciales y profesionales.
El precio no es del todo económico. Aunque el modelo se puede probar gratuitamente en el sitio web del proyecto, en nuestras pruebas solo pudimos crear una imagen (10 créditos). La plataforma permite comprar créditos mensuales: 8 dólares al mes permiten comprar 500 créditos, lo que a priori nos permitiría crear 50 imágenes de 10 créditos cada una. Cada una saldría a 0,16 dólares, cuando nano banana tiene un coste de 0,039 dólares, cuatro veces inferior aparentemente. Hay otras opciones para probarlo, como los “Spaces” de Hugging Face. Es también posible conseguir una clave API en Tencent Cloud para usar el modelo localmente.

Gemini sigue ganando como “editor”. Aunque el modelo de Tencent es interesante y destacable, nano banana sigue ganando la partida si consideramos que se ha convertido en un singular sustituto del tradicional Photoshop. Muchos usuarios ya no editan fotos sino que cargan una en Gemini y luego le dicen a la IA qué cambios quieren realizar en esa imagen.
Alibaba, más conversacional. Aunque Hunyuan Image 3.0 pueda permitir algo así —de hecho hay demos al respecto—, la interfaz está por ahora más dirigida a un único prompt para generar imágenes, no a una “conversación” como sí permite Gemini. Otro de los protagonistas de este terreno es Alibaba, que con Qwen-Image-Editor adopta el mismo enfoque que Google con Gemini y nano-banana. En ese modelo de Alibaba “hablas” con tu imagen para pedir cambios, algo que de momento no parece que el modelo de Tencent haga tan directamente (aunque no parece difícil que lo consiga).
Pero cuidado. Lo diferencial aquí es que la generación de imágenes, que parecía estar dominada por modelos propietarios, puede ser aparentemente igual de buena (o incluso superior) mediante modelos abiertos. Una vez más la apuesta China por esa filosofía es destacable y contrasta con el enfoque cerrado y propietario de la mayoría de empresas estadounidenses que desarrollan modelos de IA tanto para generar imágenes como texto (o, desde luego, vídeo).
Imagen | Hunyuan
–
La noticia
Tenemos un nuevo ganador en generación de imágenes con IA. Y no es estadounidense, sino chino
fue publicada originalmente en
Xataka
por
Javier Pastor
.
Tencent acaba de lanzar un nuevo modelo de IA capaz de generar imágenes a partir de un prompt de texto. Tradicionalmente los modelos propietarios han dominado este tipo de tarea creativa, pero el modelo de Tencent ha dado la sorpresa y según diversos benchmarks es capaz de generar imágenes mejor que el resto de competidores, incluidos los de Google y OpenAI.Hunyuan Image 3.0. Así se llama el nuevo modelo de Tencent, que en la clasificación de LMArena de modelos más potentes para la generación de imágenes a partir de texto ha logrado superar a Gemini 2.5 Flash Image Preview (popularmente conocido como nano banana), además de a otros modelos propietarios como GPT-Image-1, Flux-1-Kontext-Max o Qwen-Image.
El modelo de imagen de Tencent ha logrado ya superar a sus competidores según los expertos de LM Arena.
Votación a ciegas. Esa clasificación de LM Arena funciona mediante un sistema de votación ciega en el cual losusuarios eligen sus imágenes preferidas sin saber qué modelo los generó. Y según dicha votación, este modelo de Tencent superó a todos sus contrincantes, incluyendo al popular “nano banana” de Google. Eso sí: la votación también tiene en cuenta resultados a largo plazo, y el corto periodo que lleva disponible Hunyuan Image 3.0 hace que los resultados se califiquen como “preliminares” y no definitivos.Cómo funciona. Los responsables de Tencent explican en la descripción del modelo cómo han utilizado una nueva arquitectura de difusión que hace uso de codificadores duales (un LLM multimodal y otro que entiende mejor los caracteres de distintos idiomas) y optimización RLHF (Reinforcement Learning from Human Feedback, que refina el resultado previo) para la creación de imágenes de mayor calidad. El sistema hace uso además de un sistema de compresión para que todo el proceso consuma menos recursos sin pérdida de calidad.
En Xataka
Nano Banana no es solo un gran creador de imágenes con IA. Es el mayor peligro para Photoshop y compañía
Pesos abiertos y licencia comercial. Hunyuan Image 3.0 es un modelo que comparte su código en GitHub y que ofrece una licencia sorprendentemente permisiva. De hecho es posible hasta usarlo con fines comerciales y profesionales.
El precio no es del todo económico. Aunque el modelo se puede probar gratuitamente en el sitio web del proyecto, en nuestras pruebas solo pudimos crear una imagen (10 créditos). La plataforma permite comprar créditos mensuales: 8 dólares al mes permiten comprar 500 créditos, lo que a priori nos permitiría crear 50 imágenes de 10 créditos cada una. Cada una saldría a 0,16 dólares, cuando nano banana tiene un coste de 0,039 dólares, cuatro veces inferior aparentemente. Hay otras opciones para probarlo, como los “Spaces” de Hugging Face. Es también posible conseguir una clave API en Tencent Cloud para usar el modelo localmente.
Gemini sigue ganando como “editor”. Aunque el modelo de Tencent es interesante y destacable, nano banana sigue ganando la partida si consideramos que se ha convertido en un singular sustituto del tradicional Photoshop. Muchos usuarios ya no editan fotos sino que cargan una en Gemini y luego le dicen a la IA qué cambios quieren realizar en esa imagen.
Alibaba, más conversacional. Aunque Hunyuan Image 3.0 pueda permitir algo así —de hecho hay demos al respecto—, la interfaz está por ahora más dirigida a un único prompt para generar imágenes, no a una “conversación” como sí permite Gemini. Otro de los protagonistas de este terreno es Alibaba, que con Qwen-Image-Editor adopta el mismo enfoque que Google con Gemini y nano-banana. En ese modelo de Alibaba “hablas” con tu imagen para pedir cambios, algo que de momento no parece que el modelo de Tencent haga tan directamente (aunque no parece difícil que lo consiga).
Pero cuidado. Lo diferencial aquí es que la generación de imágenes, que parecía estar dominada por modelos propietarios, puede ser aparentemente igual de buena (o incluso superior) mediante modelos abiertos. Una vez más la apuesta China por esa filosofía es destacable y contrasta con el enfoque cerrado y propietario de la mayoría de empresas estadounidenses que desarrollan modelos de IA tanto para generar imágenes como texto (o, desde luego, vídeo).Imagen | HunyuanEn Xataka | En China no se conforman con crear robots avanzados: una compañía ha desarrollado una cabeza que gesticula como un humano
– La noticia
Tenemos un nuevo ganador en generación de imágenes con IA. Y no es estadounidense, sino chino
fue publicada originalmente en
Xataka
por
Javier Pastor
.











