

Ciencia y Tecnología
Nuestras conversaciones con Claude eran intocables. Hoy la urgencia de datos presiona para hacerlas materia prima de la IA
Solemos hablar con la inteligencia artificial como si fuera una persona más y, en ocasiones, le confiamos información muy personal. Sin embargo, rara vez nos detenemos a pensar qué ocurre con esas conversaciones. Hasta ahora, la norma en buena parte del sector había sido utilizarlas para entrenar modelos, salvo que el usuario se opusiera. Anthropic representaba una excepción: Claude tenía una política explícita de no emplear las conversaciones de sus clientes particulares para este fin. Esa excepción acaba de romperse. El motivo es directo y contundente: los datos son la materia prima de la IA.
Anthropic acaba de anunciar en su blog oficial una actualización de sus condiciones de servicio para consumidores y de su política de privacidad. Los usuarios de los planes Free, Pro y Max, incluidas las sesiones en Claude Code, deberán aceptar o rechazar explícitamente que sus conversaciones se utilicen para el entrenamiento de futuros modelos. La compañía fijó el plazo hasta el 28 de septiembre de 2025 y advirtió que, después de esa fecha, será necesario elegir la preferencia para seguir usando Claude.
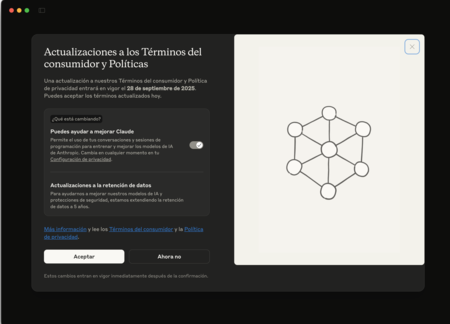
El giro de Anthropic. La modificación no afecta a todos por igual: quedan fuera los servicios sujetos a términos comerciales, como Claude for Work, Claude Gov, Claude for Education, o el acceso mediante API a través de terceros como Amazon Bedrock o Vertex AI de Google Cloud. Anthropic precisa que la nueva configuración solo se aplicará a chats y sesiones de código iniciados o retomados después de aceptar las condiciones, y que las conversaciones antiguas sin actividad adicional no se utilizarán para entrenar modelos. Es una distinción operativa relevante: el cambio actúa sobre la actividad futura.
¿Por qué este cambio? Anthropic señala que todos los modelos de lenguaje “se entrenan usando grandes cantidades de datos” y que las interacciones reales ofrecen señales valiosas para mejorar capacidades como el razonamiento o la corrección de código. Al mismo tiempo, varios especialistas llevan tiempo apuntando a un problema estructural: la web abierta se está agotando como fuente fresca y fácilmente accesible de información, de modo que las empresas buscan nuevas vías de datos para sostener la mejora continua de los modelos. En ese contexto, las conversaciones de los usuarios adquieren un valor estratégico.
Aunque Anthropic pone el acento en la seguridad (mejorar a Claude y reforzar salvaguardas contra usos dañinos, como estafas y abusos), la decisión probablemente también responde a la competencia: OpenAI y Google siguen siendo referencias en la materia y requieren grandes volúmenes de interacción para avanzar. Sin los suficientes datos, las distancias en la carrera de la IA que estamos presenciando en directo pueden aumentar.

Cinco años en lugar de treinta días. Junto al permiso de entrenamiento, Anthropic ha ampliado el periodo de retención para los datos compartidos con fines de mejora: cinco años si el usuario acepta participar, frente a los 30 días que rigen si no se activa esa opción. La compañía especifica además que los chats eliminados no se incluirán en futuros entrenamientos y que el feedback enviado también puede conservarse. Además afirma que combina procesos y herramientas automatizadas para filtrar u ofuscar información sensible y que no vende los datos de los usuarios a terceros.
Imágenes | Claude | Captura de pantalla
–
La noticia
Nuestras conversaciones con Claude eran intocables. Hoy la urgencia de datos presiona para hacerlas materia prima de la IA
fue publicada originalmente en
Xataka
por
Javier Marquez
.
Solemos hablar con la inteligencia artificial como si fuera una persona más y, en ocasiones, le confiamos información muy personal. Sin embargo, rara vez nos detenemos a pensar qué ocurre con esas conversaciones. Hasta ahora, la norma en buena parte del sector había sido utilizarlas para entrenar modelos, salvo que el usuario se opusiera. Anthropic representaba una excepción: Claude tenía una política explícita de no emplear las conversaciones de sus clientes particulares para este fin. Esa excepción acaba de romperse. El motivo es directo y contundente: los datos son la materia prima de la IA.
Anthropic acaba de anunciar en su blog oficial una actualización de sus condiciones de servicio para consumidores y de su política de privacidad. Los usuarios de los planes Free, Pro y Max, incluidas las sesiones en Claude Code, deberán aceptar o rechazar explícitamente que sus conversaciones se utilicen para el entrenamiento de futuros modelos. La compañía fijó el plazo hasta el 28 de septiembre de 2025 y advirtió que, después de esa fecha, será necesario elegir la preferencia para seguir usando Claude.
El giro de Anthropic. La modificación no afecta a todos por igual: quedan fuera los servicios sujetos a términos comerciales, como Claude for Work, Claude Gov, Claude for Education, o el acceso mediante API a través de terceros como Amazon Bedrock o Vertex AI de Google Cloud. Anthropic precisa que la nueva configuración solo se aplicará a chats y sesiones de código iniciados o retomados después de aceptar las condiciones, y que las conversaciones antiguas sin actividad adicional no se utilizarán para entrenar modelos. Es una distinción operativa relevante: el cambio actúa sobre la actividad futura.
¿Por qué este cambio? Anthropic señala que todos los modelos de lenguaje “se entrenan usando grandes cantidades de datos” y que las interacciones reales ofrecen señales valiosas para mejorar capacidades como el razonamiento o la corrección de código. Al mismo tiempo, varios especialistas llevan tiempo apuntando a un problema estructural: la web abierta se está agotando como fuente fresca y fácilmente accesible de información, de modo que las empresas buscan nuevas vías de datos para sostener la mejora continua de los modelos. En ese contexto, las conversaciones de los usuarios adquieren un valor estratégico.
Aunque Anthropic pone el acento en la seguridad (mejorar a Claude y reforzar salvaguardas contra usos dañinos, como estafas y abusos), la decisión probablemente también responde a la competencia: OpenAI y Google siguen siendo referencias en la materia y requieren grandes volúmenes de interacción para avanzar. Sin los suficientes datos, las distancias en la carrera de la IA que estamos presenciando en directo pueden aumentar.
En Xataka
NVIDIA se ha convertido en la empresa más importante del mundo. Su problema es que tiene todos los huevos en la misma cesta
Cinco años en lugar de treinta días. Junto al permiso de entrenamiento, Anthropic ha ampliado el periodo de retención para los datos compartidos con fines de mejora: cinco años si el usuario acepta participar, frente a los 30 días que rigen si no se activa esa opción. La compañía especifica además que los chats eliminados no se incluirán en futuros entrenamientos y que el feedback enviado también puede conservarse. Además afirma que combina procesos y herramientas automatizadas para filtrar u ofuscar información sensible y que no vende los datos de los usuarios a terceros.
Imágenes | Claude | Captura de pantalla
En Xataka | Microsoft prefiere un 7 propio que un 10 de OpenAI. Los 13.000 millones invertidos en OpenAI acaban de cobrar sentido
– La noticia
Nuestras conversaciones con Claude eran intocables. Hoy la urgencia de datos presiona para hacerlas materia prima de la IA
fue publicada originalmente en
Xataka
por
Javier Marquez
.










